Solving Nodes RAM consumption with RAID 100 alike and 2 PERC Controllers
The problem with exponential growth of data and memory consumption is somewhat problematic, or at least it will be in near future. Most of Industry Grade servers, such as Dell PowerEdge’s that I’m using supports up to maximum 240GB of Ram. With about 500M of data growth daily, we can expect that industry grade server very soon are not going to be enough for running a witness / seed node with enough plugins to support direct operation of wallet operation and price feed publishing.
My witness node has the following set of plugins and public api’s enabled:
Public API: database_api login_api account_by_key_api network_broadcast_api
Plugins: witness account_by_key
Current memory consumption is: 54G
Another problem with non-persistent memory is requirement to re-sync the database in case of failure. RAM is efficient and Fast, still, i need to periodically stop my node in order to backup shared_memory.bin from /dev/shm so I don’t end up with full resync in case of power outage.
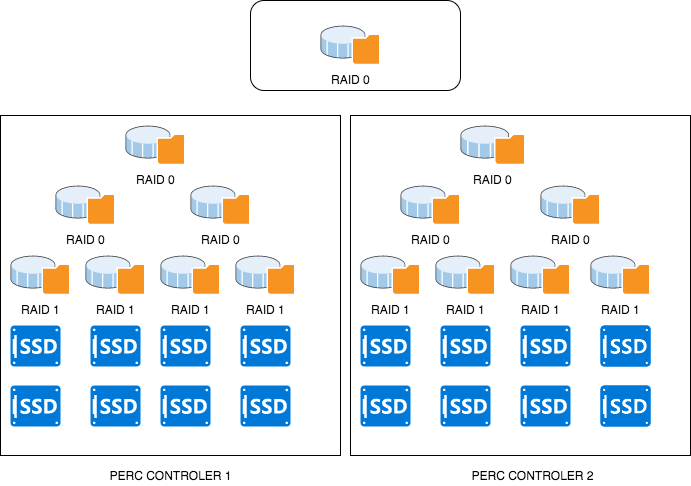
The Approach:
- 2 X PERC H740P handling 8x 1TB EVO SSD’s each.
- RAID 1 on the low layer for redundancy and persistence.
- RAID 0 on top, with software raid bridge on top of two controllers.
How it looks like:
Here we are with IOWait of my witness node (in production):

I think i can totally live with this level. 1TB persistent Storage is definitely to serve for a long way. Moreover, no more re-syncing, easier backup. Node is up, will see how it's going to perform and if there's going to be any missing blocks. So far, everything works as expected to my surprise, with customer grade SSD's, that are not even SAS, just regular SATA with which PERC is backwards compatible.
This is one of approaches to address the increased amount of data. The next one I will be trying to implement, is based on "HAProxy" like, split of traffic between multiple nodes based on the block number. As this would be Layer7 inspection and re-encryption, i don't expect miracles here but it's worth trying, as we are going to need Load Balancing sooner or later.
There was a good proposal by @gandalf or (@gtg) to load balance based on different plugins loaded on different nodes. This could be interested approach as well, but moving forward and NAT-ing the packet based on transaction type.
What's important here, is that I managed to achieve much better results with ESXi Virtualized host, rather then the Raw Ubuntu on the server. It seems that drivers are messy, or it could be other kernel tweak that I am missing. However, based on the fact it runs on ESXi HyperVisor, I am sure we can achieve even better performances with kernel tweaks.
If you would like to support me, you can do that via steemit website:
If you are an advanced user, You can do it with unlocked cli_wallet by executing:
vote_for_witness "yourusername" "crt" true true
Thanks to all supporters and all the members of Steemit Community.
Seems overkill when two good NVME drives raid 0 would likely still be faster than this setup and wouldn't even require a fancy raid controller. The problem is getting high-speed NVME on servers with low size (1U-2U) for efficient hosting is hard as most servers have slow NVME and at 300-500% the cost.
You can get 2TB NVME drives now with over 3500MB/s for around $1,200 each. Two of these in RAID 0 would give you plenty of storage for long into the future and plenty of speed for offloading the ram demands to disk.
It would also likely allow you to run two full nodes for the cost of one with your setup. Raid 0 I generally would never recommend but with how full nodes are, if you have a crash you are rebuilding anyway.
I would even bet one single NVME Pro drive without raid would still be faster than this setup.
I like @gtg's idea of using JUSSI to distribute transactions by type to multiple servers scaling horizontally instead of vertically.
I would not mix up a Witness and full node, I assume you know that once you start thinking about enabling other plugins you should move your witness elsewhere, but I wanted to be clear about that point.
The problem with NVME raid 0 is that's only possible to achieve with software raid. Meaning, no battery backing, no controller cache. Also, Raid 1 on the bottom is important to preserve data, combined with battery. In regards to crash-es, in case of power outage, scripts read the USP status via SNMP and issues SIGINT to steemd, so that the data is safely put on disk. I also did a couple of edits here and there in the code to ensure corruption free files even in case of steemd crash. (although not properly tested yet, but will submit merge request on github if it shows well with my server).
While theoretically you are right in terms of speed, I still prefer industry grade approach. It's much easier to scale. I also have a hot spare, dual power supplies, ECC memory. These things are important. (Learned the hard way working with mission critical systems).
It could be "a psychology" problem of mine :) but I don't trust the system unless I can replace the faulty drive, or power supply without guest OS even being aware that anything happened at all.
As for the seed nodes, I did managed to perform p2p load balancing based on block number using CCR1036-12G-4S-EM and some scripting. (not being used yet as it needs to be properly tested).
The way I see witness work in 1 year from now, only the 'by the book' industry grade systems with well planned topology would survive and be able to scale. While it's possible to improvise, it comes with the price, many of us (including myself) learn the hard way.
Another problem is that people who are experienced with mission critical systems outside of crypto industry are hard to get into the projects such this one. While the people from crypto are usually tends to experiment with DIY solutions. While it's fun, the problem with the lack of first category is important knowledge transfer that shall take place to ensure that not every single lesson is paid again.
I'll try to implement as much as possible from the industry best practices into this (and other projects i'm involved into) in order to better understand the technology challenges.
While we are experimenting a DIY solutions, IBM (and others) are watching what we are doing with their proprietary blockchain solutions, and once we prove the good working model, they would be able to deploy steem-like platform in a matter of seconds, that will be more stable and scalable in every possible way. That's what i'm afraid of, that current technologies are just a testing polygon for corporate players.
(These are my predictions, and articles such as this one are my contribution for the future if it happens my view to be correct). - or it does not have to be at all.
The problem is the hardware requirements for a full node on Steem are so ridiculous that you have to consider DIY, especially since there is no data loss in a complete failure scenario.
Enterprise quality hardware for a full node would be $30-40K. A Dell server that meets requirements today is around $20k and that's without any redundancy or hardware RAID. The fact the hardware would be outgrown in 6 months makes it even worse.
There is a good chance all these servers we are setting up for full nodes with 512GB of ram won't be sufficient in 6 months. AppBase promises to help in this regards, as does account history changing to 30 days instead of since block 0 on full nodes, but then again Steem Mobile Wallet was coming out in November.
Spending $20k-$30k+ on hardware that may last 6 months isn't a very smart move, especially when there is no financial recovery by running a full node, only a witness node and those positions with the funding to do such a thing are pretty much locked in stone.
Just have in mind, that for the price of two NVE, you can get a refurbished enterprise grade server with controller and even 240GB ECC ram on ebay. (The cost of the new one would be 20-30k).
But you are right on many points. Unless there are other motives, most likely investing in enterprise grade infrastructure is not a wise choice and it's likely not to generate ROI.
For example, ECC Ram is crucial thing so you don't need to rebuild from scratch even in case of crash. Not sure how many people are aware of that. (not talking about RAM as a storage, just for the operation of steemd). When ECC Ram is used, the chances of file corruption are unlikely to happen even when kill -9 is used.
On another side, I am a bit fascinated about these things not being documented, and I got an impression that there is a strong amount of 'selfishness' when it comes to knowledge exchange, which is totally opposite from Open Source Ideology, that blockchain evolved from.
Wow, nice storage :-)
but...
For your
steemdconfiguration this setup is irrelevant. Those plugins are not use much memory anyway, alsoas mentioned on chat, that's because you have wrong build.
For this config you should use
-DLOW_MEMORY_NODE.But of course for full node that beast can be very effective.
However, please note that currently your results currently are heavily biased by memory caching.
Would you mind running:
dd if=/dev/zero of=tst.tmp bs=4k count=10k oflag=dsyncout there?
(General approach is good, I'm using fast storage on my nodes to compensate lack of RAM)
Absolutely,
(Keep in mind that the controllers itself are 8GB DDR4 Ram (each), so the results could differ from what's actually happening on the first level array (where it's probably much slower). But I guess you were thinking of that with memory cached results.
As for the -DLOW_MEMORY_NODE flag, I am trying to skip that, as I do plan to enable as much plugins as possible, eventually going with full node (all the available plugins).
I guess we need to see what is going to happen then.
That's what I'm afraid. I was running full node on HDDs with decent RAID, and everything works fine as long as cache (on various levels) can keep up with load. But of course with much, much lower latency on SSDs it might be a viable solution. (HDD are useful because you can spot latency issues much earlier).
Agree in full. Still I found such experiments are crucial for steemit scalability, and I'm very glad to see more people are thinking of it, as well as having 'organ' that is supposed to perform thinking ;)
The results above could be explanation of ESXI / Bare Metal differences, as it's likely that Ubuntu Drivers are not handling cache correctly.
It would be interesting to see if there would be any difference if I replace SSD with Mechanical SAS drives. (Probably not going to manage until the end of the week, but will update). But this will give full insight on SSD/HDD latency difference once the cache can't keep up with the data.
As for the memory consumption, I think that df -h is totally irrelevant here, as 'HotPlug Memory' and 'Reserve All' is configured at the VCenter. This is the VCenter output of memory usage of node. (1.6 GB Only). VCenter can be very mysterious with stats sometimes.
While I do think better SSD drives could possibly offer a good alternative to scale Steemit, I still put hopes in Stunnel -> HaProxy -> Stunnel -alike clustering (Just for the purpose of understanding). Following your idea of nodes with different plugins and examining tcp dumps, I found it possible to redirect the traffic based on transaction type.
Anyhow, experimentation and communication like this one is a very good signal for steemit future scalability and therefore sustainability.
Nice having you around.
Disclaimer: I don't hide my real motives, experimentations performed here are done both for the benefit for community but as well to expand my knowledge in BIG Data, as I do full time consultancy for a living.
Sounds good :-)
Take a look at jussi (JSON-RPC 2.0 Reverse Proxy).
Very Interesting for RPC (will definitely experiment), but it's P2P that is catching my toughs.
No, wrong way. Turn around. With current architecture we can't split that, and definitely you won't do that on a network level.
My psychiatrist told me the same ;)
Joke aside, i'll need to dig into it on network level in order to understand it. Even if i don't manage (Assuming I wont, as you seems like someone who already tried), I am surely to better understand the architecture and the payloads.